
中广联演员委员会就AI换脸合成、影视素材魔改发声明
4月2日,据中国广电联合会演员委员会,当前,AI换脸合成、声纹克隆复刻、影视素材任意篡改、魔改、擅自抓取演员影像声频用于AI模型训...
扫一扫用手机浏览
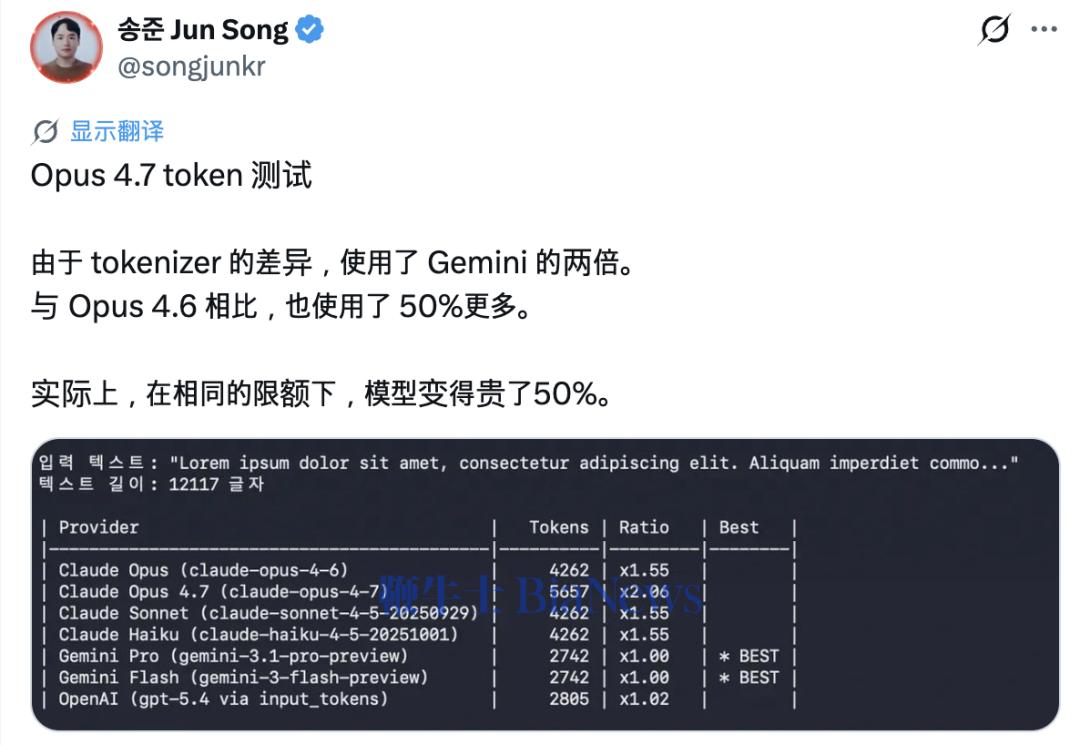
后续,Claude Code 之父 Boris Cherny 也表示将提高额度来抵消这部分的影响。
 但 token 膨胀还算小事。更让人哭笑不得的,是 Opus 4.7 那张嘴。它动不动「我就在这里,不躲,不藏,不绕,不逃,稳稳地接住你、翻译成人话、我太懂你这种感觉了,不是,而是」,一股浓烈的 ChatGPT 味扑面而来。
但 token 膨胀还算小事。更让人哭笑不得的,是 Opus 4.7 那张嘴。它动不动「我就在这里,不躲,不藏,不绕,不逃,稳稳地接住你、翻译成人话、我太懂你这种感觉了,不是,而是」,一股浓烈的 ChatGPT 味扑面而来。
 平心而论,Opus 4.6 也有这个毛病,Sonnet 4.6 反而症状更轻。只是到了 4.7,这股腔调明显更浓,不懂好好说话的问题愈发突出。
平心而论,Opus 4.6 也有这个毛病,Sonnet 4.6 反而症状更轻。只是到了 4.7,这股腔调明显更浓,不懂好好说话的问题愈发突出。

APPSO 之前也报道过,过于油腻的说话风格与 RLHF(人类反馈强化学习)有关。训练时,人类评审者倾向于给听起来顺耳、令人愉快的回答打高分,模型就学会了这套讨好人的腔调。这是一个关于AI 在取悦谁的问题。
但 Opus 4.7 让人关注的地方不止于此。token 越用越多,说明它在「想」得更多。只是那些浮夸的安慰腔调又让人怀疑,它想出来的东西,究竟算不算真的在思考,还是仅仅学会了一套让你感觉它在思考的表演方式。
这个问题,远比局限于 Opus 4.7 好不好用的命题要更深刻。而答案的线索,最先出现在让人最想不到的论坛:4Chan。 来自 @acnekot,上同
改变 AI 轨迹的算术题
简单科普一下,4chan 是互联网上最臭名昭著的地方之一,里面充斥着脏话、阴谋论和各种难以描述的内容。但偏偏就是这里,藏着一个改变了整个 AI 行业走向的发现。
把时间拨回 2020 年夏天,距离 ChatGPT 震撼世界还有两年多。
当时的 4chan 游戏板块依旧乌烟瘴气,满屏都是离奇的成人幻想和最原始的荷尔蒙冲动。不过那时,这群人集体迷上了一款叫《AI Dungeon》的文字 RPG 游戏。
这款游戏的底层,接入了当时刚刚问世的 OpenAI GPT-3 模型。
来自 @acnekot,上同
改变 AI 轨迹的算术题
简单科普一下,4chan 是互联网上最臭名昭著的地方之一,里面充斥着脏话、阴谋论和各种难以描述的内容。但偏偏就是这里,藏着一个改变了整个 AI 行业走向的发现。
把时间拨回 2020 年夏天,距离 ChatGPT 震撼世界还有两年多。
当时的 4chan 游戏板块依旧乌烟瘴气,满屏都是离奇的成人幻想和最原始的荷尔蒙冲动。不过那时,这群人集体迷上了一款叫《AI Dungeon》的文字 RPG 游戏。
这款游戏的底层,接入了当时刚刚问世的 OpenAI GPT-3 模型。
 在虚拟世界里,玩家只要敲下「拿起剑」或者「让巨魔滚开」,算法就会顺着往下编故事。毫不意外,到了 4chan 老哥手里,这个游戏光速沦为满足各种赛博性幻想的试验田。
令人没想到的是,这群特立独行的玩家,做了一件在当时看来极为反直觉的事:
他们开始逼着游戏里的 NPC 做数学题。
在虚拟世界里,玩家只要敲下「拿起剑」或者「让巨魔滚开」,算法就会顺着往下编故事。毫不意外,到了 4chan 老哥手里,这个游戏光速沦为满足各种赛博性幻想的试验田。
令人没想到的是,这群特立独行的玩家,做了一件在当时看来极为反直觉的事:
他们开始逼着游戏里的 NPC 做数学题。
 懂行的人都知道,初出茅庐的 GPT-3 是个纯纯的「文科生」,连最基础的加减乘除都能算得一塌糊涂。
但诡异的事情发生了。
有个玩家偶然发现,如果不去死要答案,而是勒令 NPC 保持人设、把解题步骤一步步写出来,这个大模型不仅算对了,甚至连语气都贴合了虚拟角色的设定。
那位玩家在论坛里激动地破口大骂:「它**不仅解出了数学题,还是用完全符合那个角色性格的语气解出来的!」意识到了这个发现的含金量后,玩家们也开始将这些带有详细步骤的截图发到了 Twitter 上。
懂行的人都知道,初出茅庐的 GPT-3 是个纯纯的「文科生」,连最基础的加减乘除都能算得一塌糊涂。
但诡异的事情发生了。
有个玩家偶然发现,如果不去死要答案,而是勒令 NPC 保持人设、把解题步骤一步步写出来,这个大模型不仅算对了,甚至连语气都贴合了虚拟角色的设定。
那位玩家在论坛里激动地破口大骂:「它**不仅解出了数学题,还是用完全符合那个角色性格的语气解出来的!」意识到了这个发现的含金量后,玩家们也开始将这些带有详细步骤的截图发到了 Twitter 上。

 V1 版本
大量 2020 年至 2021 年间的互联网历史快照和社区记录被翻了出来。面对确凿的先例,Google 在后续修订版中悄悄删除了「第一人」的表述,但对那群 4chan 玩家的功劳依然装聋作哑。
V1 版本
大量 2020 年至 2021 年间的互联网历史快照和社区记录被翻了出来。面对确凿的先例,Google 在后续修订版中悄悄删除了「第一人」的表述,但对那群 4chan 玩家的功劳依然装聋作哑。
 V3 版本
与此同时,还有另一位独立发现者。
当时还是计算机系学生的 Zach Robertson,同样通过玩《AI Dungeon》接触了 GPT-3,并在 2020 年 9 月在 LessWrong 上发表了博客,详细记录了如何将问题「拆解为多步骤并链接起来」放大模型能力。
V3 版本
与此同时,还有另一位独立发现者。
当时还是计算机系学生的 Zach Robertson,同样通过玩《AI Dungeon》接触了 GPT-3,并在 2020 年 9 月在 LessWrong 上发表了博客,详细记录了如何将问题「拆解为多步骤并链接起来」放大模型能力。

 逻辑?根本不存在。但答案却完美迎合了人类的期待。
我们总以为,是我们在教机器怎么像人一样思考。但看完这些从答案倒推过程的「伪证明」,但机器却并未学会思考,它只是学会了怎么顺着人类的心思说话。
所以到最后,到底是我们在使用工具,还是机器给我们讲了一个我们最爱听的睡前故事? 值得一提的是,在自然语言处理的神经可解释性领域,评判模型是否真的在推理,有一个致命指标叫「忠诚度」(Faithfulness)。
其含义是指:模型输出给用户的「思维链」文本,是否真实、忠实地反映了模型内部隐式空间中的真实计算和决策路径。顺理成章地,Claude 3.5 Haiku 的这种劣迹表现也被研究人员定级为「不忠诚的推理」。
后续大量实验表明,即便人为切断思维链中的某些关键步骤,模型预测最终答案的轨迹有时根本不会改变。模型有时给出了通篇逻辑完全错误的思维链,依然能在结尾「蒙对」最终结果。
包括到了 2024 年,还是这群 4chan 老哥,自己捣鼓出了一份硬核的 AI 调教指南。这份指南开篇第一句就是经典的:「你的机器人只是个幻觉(Your bot is an illusion)。」
逻辑?根本不存在。但答案却完美迎合了人类的期待。
我们总以为,是我们在教机器怎么像人一样思考。但看完这些从答案倒推过程的「伪证明」,但机器却并未学会思考,它只是学会了怎么顺着人类的心思说话。
所以到最后,到底是我们在使用工具,还是机器给我们讲了一个我们最爱听的睡前故事? 值得一提的是,在自然语言处理的神经可解释性领域,评判模型是否真的在推理,有一个致命指标叫「忠诚度」(Faithfulness)。
其含义是指:模型输出给用户的「思维链」文本,是否真实、忠实地反映了模型内部隐式空间中的真实计算和决策路径。顺理成章地,Claude 3.5 Haiku 的这种劣迹表现也被研究人员定级为「不忠诚的推理」。
后续大量实验表明,即便人为切断思维链中的某些关键步骤,模型预测最终答案的轨迹有时根本不会改变。模型有时给出了通篇逻辑完全错误的思维链,依然能在结尾「蒙对」最终结果。
包括到了 2024 年,还是这群 4chan 老哥,自己捣鼓出了一份硬核的 AI 调教指南。这份指南开篇第一句就是经典的:「你的机器人只是个幻觉(Your bot is an illusion)。」
 大模型「长思考」背后的暴力美学
如果 AI 的思考过程只是一场表演,那为何它确实能在客观上提高模型解决高难度数学题或复杂编程任务的准确率?这或许和你向 AI 提问时给的细节越多,回答越准是同一个道理。
早在 2020 年 7 月,当那个 4chan 玩家逼着 NPC 算数学题时,他就已经心照不宣地道破了天机:「这很合理,因为它基于人类语言,所以你必须像对待人类一样和它说话,才能得到正确的回应。」
大模型「长思考」背后的暴力美学
如果 AI 的思考过程只是一场表演,那为何它确实能在客观上提高模型解决高难度数学题或复杂编程任务的准确率?这或许和你向 AI 提问时给的细节越多,回答越准是同一个道理。
早在 2020 年 7 月,当那个 4chan 玩家逼着 NPC 算数学题时,他就已经心照不宣地道破了天机:「这很合理,因为它基于人类语言,所以你必须像对待人类一样和它说话,才能得到正确的回应。」
 针对这个悖论,Perplexity 的 CEO Aravind Srinivas 曾给出过一个极其本质的解释:多出来的这些词汇,在物理层面上给了模型更多的上下文(Context),从而将其「词语预测机制」(Word Prediction Mechanism)引导到了一个更优质的方向。
针对这个悖论,Perplexity 的 CEO Aravind Srinivas 曾给出过一个极其本质的解释:多出来的这些词汇,在物理层面上给了模型更多的上下文(Context),从而将其「词语预测机制」(Word Prediction Mechanism)引导到了一个更优质的方向。
 大语言模型基于 Transformer 的自回归底层架构,决定了它在生成当前词时,只能依赖于之前已经生成的所有词汇序列。
当模型被要求直接回答一个极度复杂的问题(例如涉及多步逻辑推导的奥数题)时它其实是在极其短暂的瞬间,强行从复杂的计算里直接「变」出最终的答案。因为中间完全没有过程打底,
这种「一步登天」的盲猜,翻车率自然极高。
相反,当模型被强迫写下「首先我们需要计算 A,此时 A = 5;接着我们将 A 代入公式 B……」这样一长串的「思维链」时,模型在生成最终答案的那个 Token 时,其注意力机制(Attention Heads)可以回顾刚刚生成的、结构极其严密的上万个中间 Token。
大语言模型基于 Transformer 的自回归底层架构,决定了它在生成当前词时,只能依赖于之前已经生成的所有词汇序列。
当模型被要求直接回答一个极度复杂的问题(例如涉及多步逻辑推导的奥数题)时它其实是在极其短暂的瞬间,强行从复杂的计算里直接「变」出最终的答案。因为中间完全没有过程打底,
这种「一步登天」的盲猜,翻车率自然极高。
相反,当模型被强迫写下「首先我们需要计算 A,此时 A = 5;接着我们将 A 代入公式 B……」这样一长串的「思维链」时,模型在生成最终答案的那个 Token 时,其注意力机制(Attention Heads)可以回顾刚刚生成的、结构极其严密的上万个中间 Token。
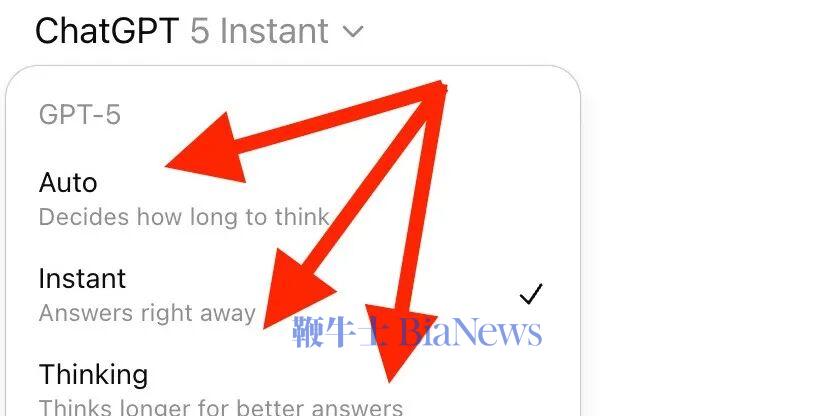 这些被戏称为「废话」的思考过程,实际上充当了模型的「草稿纸」这就好比你跟 AI 聊天时,给的背景提示越详细,它答得就越靠谱,两者的道理是一模一样的。这也是计算机科学里最古老的智慧:拿时间换准确率。
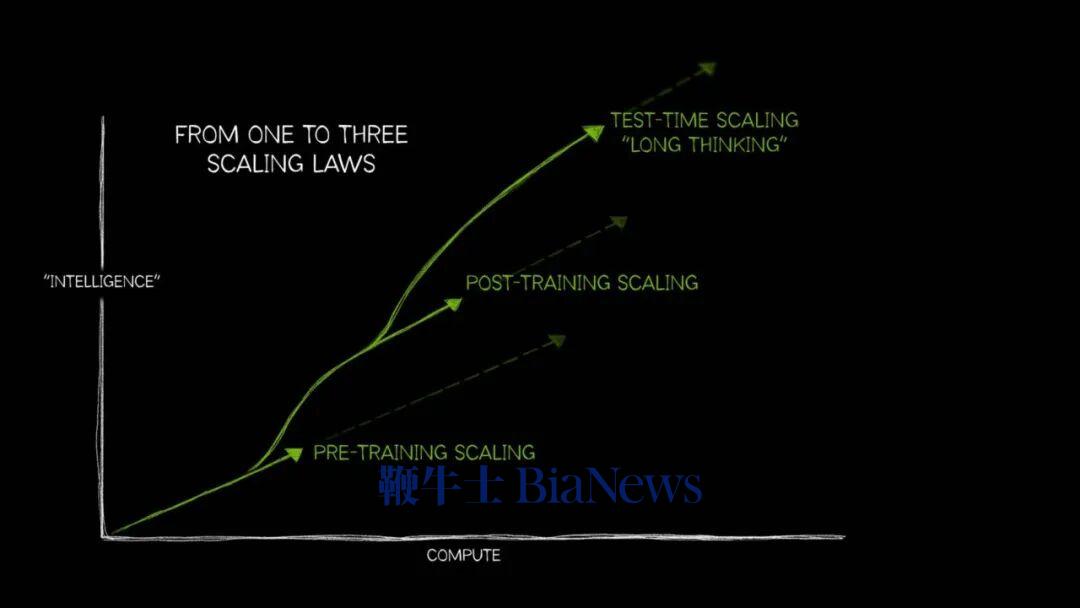
近两年来,随着预训练阶段缩放定律的边际效益逐渐递减,「测试时计算扩展」(Test-Time Compute Scaling,也称「长思考」)开始步入主流视野。
其内在逻辑一脉相承:只要在推理阶段为模型分配更多算力,允许其在输出最终答案前探索多条路径,准确率便会显著提升——这在多步逻辑推导的开放性问题上表现得尤为明显。
这些被戏称为「废话」的思考过程,实际上充当了模型的「草稿纸」这就好比你跟 AI 聊天时,给的背景提示越详细,它答得就越靠谱,两者的道理是一模一样的。这也是计算机科学里最古老的智慧:拿时间换准确率。
近两年来,随着预训练阶段缩放定律的边际效益逐渐递减,「测试时计算扩展」(Test-Time Compute Scaling,也称「长思考」)开始步入主流视野。
其内在逻辑一脉相承:只要在推理阶段为模型分配更多算力,允许其在输出最终答案前探索多条路径,准确率便会显著提升——这在多步逻辑推导的开放性问题上表现得尤为明显。
 人类面对难题时的思考方式,大概也是这个道理:两加两等于几,脱口而出;拟一份能让公司利润增长 10% 的商业计划,则需要反复权衡、推翻、重建。
区别在于,AI 把这个「权衡」的代价直接换算成了算力账单。一次简单的推断可能只需要标准计算量的百分之一;而遇上复杂的编程调试或多步数学推导,计算量可能暴涨超过一百倍,耗时从几秒拉长到几分钟乃至几小时。
尽管如此,AI 是否真的像人类在「思考」,目前没有人能给出确定答案。但「不忠诚的推理」实验已经清楚地告诉我们:推理模型展示在屏幕上的推导过程,可能是真实推导,可能是随机生成,也可能是反向凑答案。
在自动驾驶、医疗诊断、法律判决这些高风险场景里,如果我们把一长串流畅的思维链当成 AI 想清楚了的证明,后果会是灾难性的。而承认我们对这项技术的理解仍然有限,才是正确使用 AI 的前提。
人类面对难题时的思考方式,大概也是这个道理:两加两等于几,脱口而出;拟一份能让公司利润增长 10% 的商业计划,则需要反复权衡、推翻、重建。
区别在于,AI 把这个「权衡」的代价直接换算成了算力账单。一次简单的推断可能只需要标准计算量的百分之一;而遇上复杂的编程调试或多步数学推导,计算量可能暴涨超过一百倍,耗时从几秒拉长到几分钟乃至几小时。
尽管如此,AI 是否真的像人类在「思考」,目前没有人能给出确定答案。但「不忠诚的推理」实验已经清楚地告诉我们:推理模型展示在屏幕上的推导过程,可能是真实推导,可能是随机生成,也可能是反向凑答案。
在自动驾驶、医疗诊断、法律判决这些高风险场景里,如果我们把一长串流畅的思维链当成 AI 想清楚了的证明,后果会是灾难性的。而承认我们对这项技术的理解仍然有限,才是正确使用 AI 的前提。
(来源:APPSO)
4月2日,据中国广电联合会演员委员会,当前,AI换脸合成、声纹克隆复刻、影视素材任意篡改、魔改、擅自抓取演员影像声频用于AI模型训...

“ 现在就是跟打地鼠一样,发现某个时间段 AI 视频生成软件排队少,大家就调整到那个时间段工作。” 李追远( 化名 )说...

近日,央视曝光“澳洲优思益”虚构海外产地、伪造品牌背景,所谓墨尔本工厂实为汽修厂,产品实为国内代工生产。“澳洲优思益”是抖音、天猫...
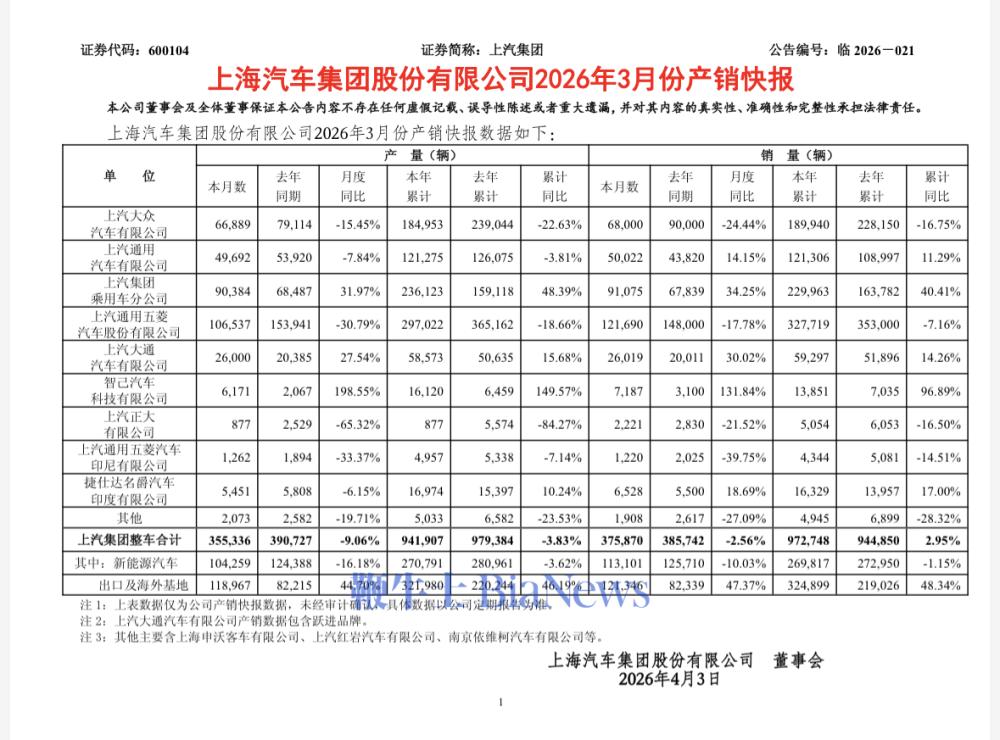
4月2日,上汽集团公布3月销量37.6万辆,同比下降2.56%;新能源汽车销量113101辆,同比下降10.03%。 其中,...
一、字节 今天,宇宙厂发布了AI产品体验新政策,以后员工在业余时间使用各种AI产品,都可以享受到公司报销,其中产研序列每年最高1...
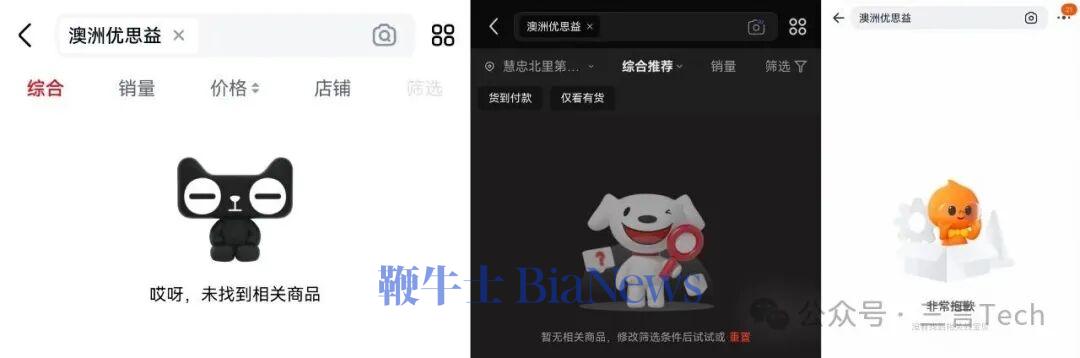
4月1日,央视新闻曝光网红保健品品牌“YouthIt优思益”系统性虚假宣传。该品牌长期以“澳大利亚原装进口”作为核心卖点,其包装标...